编程模型
早期的 GPU 以拥有大量的浮点计算单元为特征,这种设计主要是为大规模图形计算服务。后来随着人们对 GPU 进行通用编程的需求日益增加,NVIDIA 公司于 2007 年发布了CUDA(Compute Unified Device Architecture,统一计算设备架构),支持编程人员利用更为通用的方式对 GPU 进行编程,更好地发挥底层硬件强大的计算能力,从而高效地解决广泛领域中的计算问题和任务。
计算模型
作为编程框架的核心,计算模型需要根据计算核心的硬件架构提取计算的共性工作方式。CUDA 定义了以主从方式结合 SIMT 硬件多线程的计算方式。 在 GPGPU 中,承担并行计算中每个计算任务的计算单元称为线程。每个线程在一次计算任务过程中会执行相同的指令。虽然每个线程输入数 据不同,输出的结果也不同,但是每个线程需要执行的指令完全相同。也就是说,一条指令被多个线程同时执行,这种计算模式与 SIMD 并行非常相似,但在 GPGPU中被称为单指令多线程(Single Instruction Multiple Threads,SIMT)计算模型。CUDA 编程模型结合了 GPGPU 架构,对 SIMT 计算模型进行了合理的封装。CUDA 引入了线程网格(thread grid)、线程块(thread block)、线程(thread),可以将计算任务灵活地映射到 GPGPU 层次化的硬件执行单元实现高效的并行,提高了处理器的执行效率。
在CUDA编程模型中,通常将代码划分为主机端(host)代码和设备端(device)代码,分别运行在 CPU 和 GPGPU 上。这个划分是由编程人员借助 CUDA 提供的关键字进行手工标定的,接着编译器会分别调用 CPU 和 GPGPU 的编译器完成各自代码的编译。在执行时,借助运行时库完成主机端和设备端程序的分配。CPU 硬件执行主机端代码,GPGPU 硬件将根据编程人员给定的线程网格组织方式等参数将设备端代码进一步分发到线程中。每个线程执行相同的代码,但处理的是不同的数据。通过开启足够多的线程获得可观的吞吐率,这就是 GPGPU 所采用的 SIMT 计算模型。主机端代码通常分为三个步骤:数据复制、GPGPU 启动及数据写回。计算流程如图1。
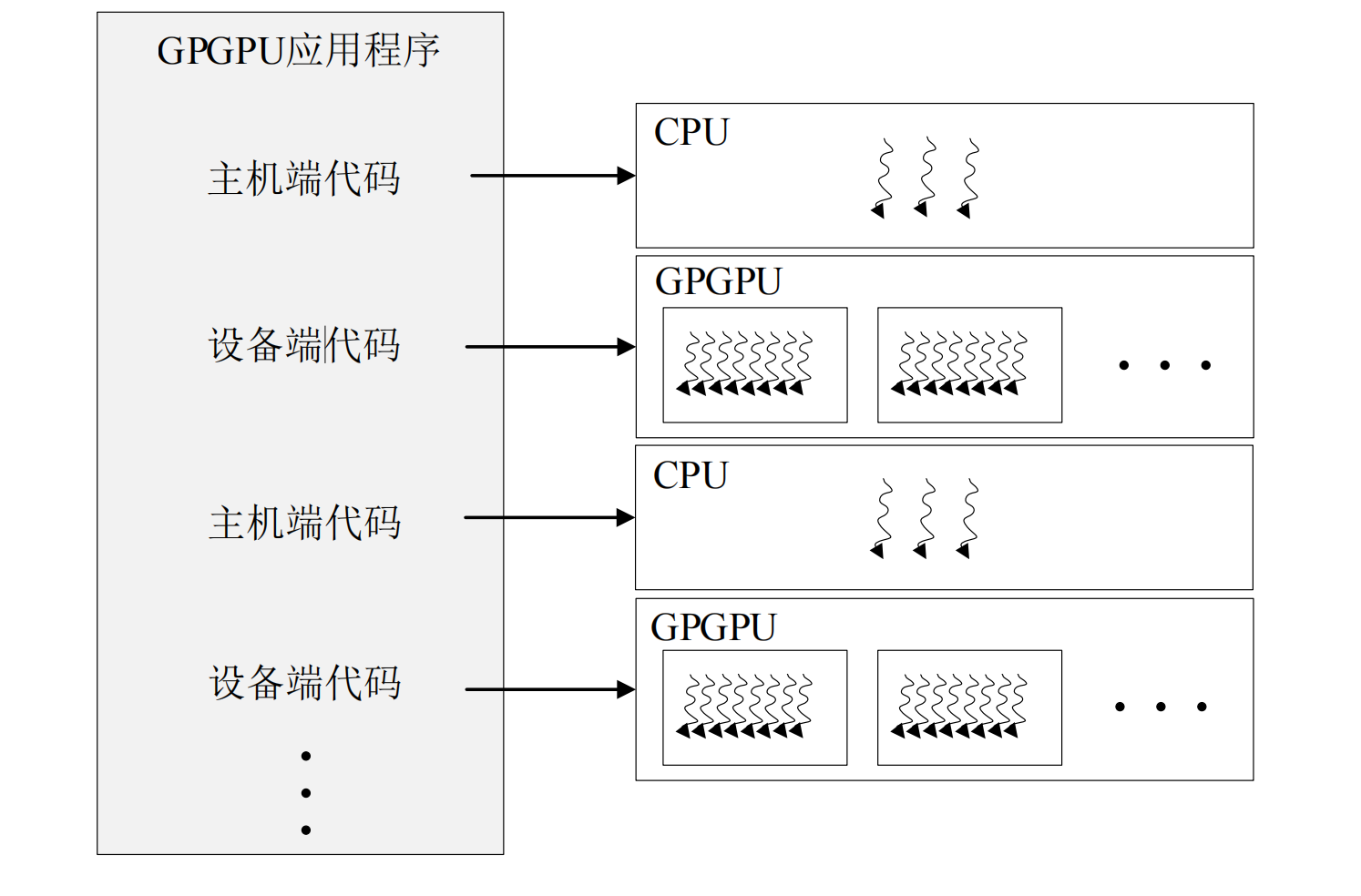{kind=link}

线程模型
大规模的硬件多线程是 GPGPU 并行计算的基础。整个 GPGPU 设备端的计算都是按照线程为基础组织的,所有的线程执行同一个内核函数。一方面,GPGPU 的线程模型定义了如何利用大规模多线程索引到计算任务中的不同数据。另一方面,线程组织与 GPGPU 层次化的硬件结构相对应。因此,GPGPU 所定义的线程模型成为计算任务和硬件核心之间的桥梁,使得 GPGPU 的编程模型在保持较高抽象层次的同时,也能够完成计算任务向硬件结构的高效映射。
CUDA 都采用了层次化的线程结构。例如,CUDA 定义的线程结构分为三级:线程网格(thread grid)、线程块(thread block)和线程(thread),它们的关系如图 2所示。
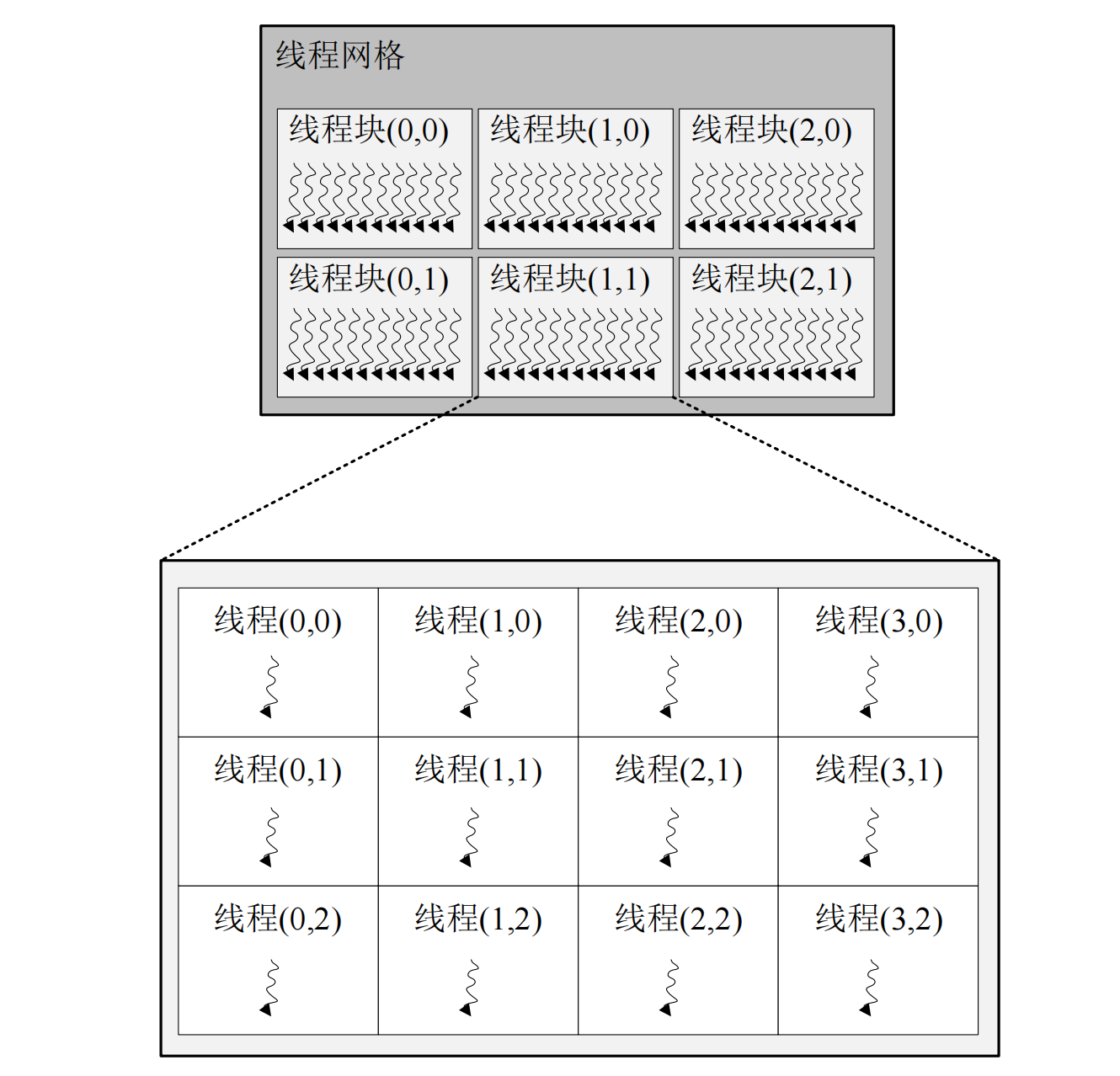{kind=link}

如图 2 所示,线程网格是最大的线程范围,包含了主机端代码启动内核函数时唤醒的所有线程。线程网格由多个线程块组成,其数量由 gridDim 参数指定。gridDim 是一种 dim3类型的数据,而 dim3 数据类型是由 CUDA 定义的关键字。它本质上是一个数组,拥有 3 个无符号整型的字段代表块的维度为三维,其组织结构为 x 表示行,y 表示列,z 表示高。在图 2 中,上半部分的线程网格由二维的线程块构成,则将 gridDim 的 z 设置为 1。如果只需要一维的线程块,只需要将 gridDim 设置为标量值即可。 线程块是线程的集合。为了按照合适的粒度将线程划分到硬件单元,GPGPU 编程模型将线程组合为线程块,同一线程块内的线程可以相互通信。与线程网格的组织方式类似,线程块的配置参数 blockDim 也是一个 dim3 类型的数据,代表了线程块的形状。在图 2 中, 下半部分是线程块的一种二维组织方式,并且每个线程块的组织方式统一。