Concepts of GPGPU
GPGPU (General-purpose graphics processing unit) was born out of GPU (Graphics Processing Unit). In the early days, due to the promotion of the game industry, GPU became a processor chip specially designed to improve graphics rendering efficiency. Today, the demand for graphics and image processing can be seen everywhere. Therefore no matter in servers, personal computers, game consoles or mobile devices (such as tablets, smart phones, etc.), GPU has become an indispensable chip. With the continuous evolution of functions, GPU has gradually developed into a general-purpose graphics processor for parallel computing acceleration, i.e. GPGPU.
GPGPU and Parallel Computers
Almasi and Gottlieb define a parallel computer as: "A parallel computer is a collection of processing units that communicate and cooperate to solve a large problem rapidly". Base on this definition, the GPGPU architecture also conforms to the definition of a parallel computer, and it clearly adopts a design method similar to Single Instruction, Multiple Data, i.e.SIMD, becoming the most successful parallel computer today. SIMD is a typical parallel architecture that uses one instruction to operate on multiple data. Vector processors and array processors are typical examples of SIMD. Many microprocessors also add instruction set extensions for SIMD mode. In practical applications, SIMD usually requires that the problem contains a large number of the same operations (such as vector and matrix operations) on different data. Typically, SIMD requires high-speed I/O and large storage capacity for efficient parallelism. The GPU also draws on the SIMD approach to achieve powerful parallel processing capabilities by building many SIMD processing units and multi-thread abstraction.。
Comparison of GPU and CPU Architectures
In the face of parallel tasks, the architectural design principles of CPU and GPU are fundamentally different. The CPU focuses on versatility to handle various data types, and must also support complex control instructions, such as conditional transfer, branch, loop, logic judgment, and subroutine call, etc. Therefore, the CPU micro-architecture is highly complex , instruction-oriented, and designed for high efficiency of execution. GPUs were originally designed for the field of graphics processing. Graphics computing is characterized by intensive operations on a large amount of data of the same type, so the GPU micro-architecture is designed for computing with this characteristic. The difference in design philosophy leads to very different architectures between CPU and GPU. CPUs have fewer cores, typically 4 and 8 cores, while GPUs consist of thousands of smaller, more efficient cores. These cores are designed for simultaneous multitasking, so GPUs are also known as many-core processors.
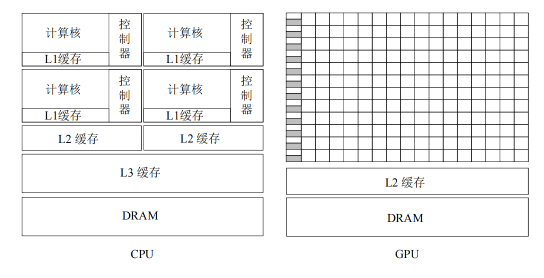
The architecture comparison of multi-core CPU and many-core GPU is shown in the figure1.can be seen that most of the transistors in the CPU are used to build control circuits and storage units, and only a small number of transistors are used to complete the actual calculation work, which makes the CPU extremely limited in large-scale parallel computing capabilities, but is better at logic control and able to adapt to complex computing environments.Since the CPU generally handles low-latency tasks, a large number of first-level (L1), second-level (L2), and third-level (L3) cache spaces are required to reduce the delay in accessing instructions and data1.The control of the GPU is relatively simple, and the demand for cache memory is relatively small, so most of the transistors can form various special circuits and multiple pipelines, so that the computing power of GPU has made a breakthrough. Due to the high parallelism of graphics rendering, the GPU can increase processing power and memory bandwidth by simply adding parallel processing units and memory control units.
{kind=link}
