SIMT correlation analysis
GPGPU follows the SIMT computing model, which includes fetch, decode, and execution of instructions according to the organization of the warp.This method allows programmers to complete most of the code in a serialized manner, and also allows each thread to perform different tasks independently. In the execution phase, if conditional branch statements such as if...else... are encountered, the code paths that different threads need to execute may be inconsistent, and thread branching or forking will occur.
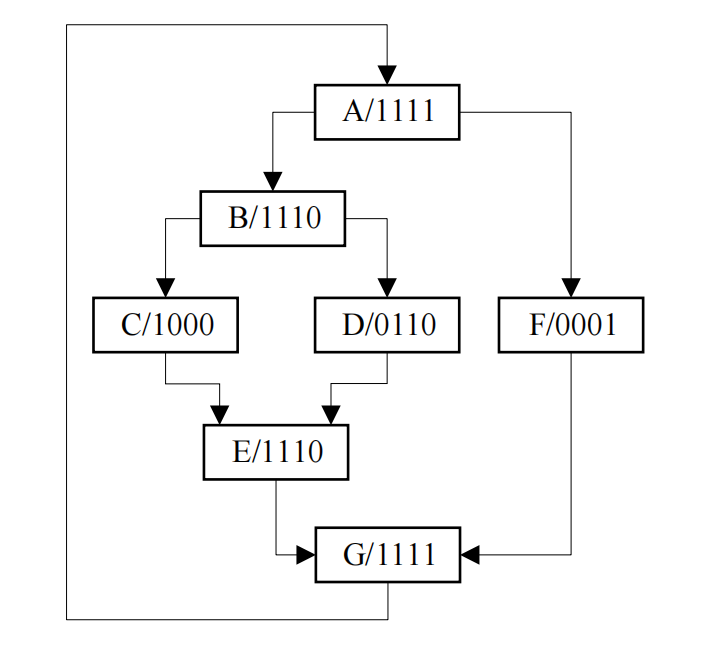
Figure 11shows the CUDA code (left) and the corresponding PTX code (right) of a kernel function with nested branches。Suppose there are 4 threads in the warp.Initially, 4 threads execute the code in basic block A, and no thread branching occurs at this time. But when block A reaches the end of execution, the if...else... statement in line 6 needs to be executed, which corresponds to the branch instruction bra in line 6 of PTX. When the three threads judge the condition to be true during execution, they will execute the code in block B.The rest one thread judges the condition to be false and executes the code in block F. Branch divergence occurs at this time.Similarly, Branch divergence also occurs after the execution of instruction block B code, some threads will execute C, and another part of threads will execute D.图Figure 22shows the branch flow graph extracted by this CUDA code and PTX code。Each box indicates the instruction block to be executed and which thread will execute the code block. For example, A/1111 means that all 4 threads will execute instruction block A, and C/1000 means that only the first thread will execute instruction block C. The lines between each box represent blocks of instructions executed sequentially。
{kind=link}
{kind=link}

