Programming Model
Early GPUs were characterized by having a large number of floating-point computing units, and this design was mainly for large-scale graphics computing. Later, as people's demand for general-purpose programming on GPUs increased, NVIDIA released CUDA (Compute Unified Device Architecture) in 2007 to support programmers to program GPUs in a more general way. It can make better use of the powerful computing power of the underlying hardware to efficiently solve computing problems and tasks in a wide range of fields.
Computing Model
As the core of the programming framework, the computing model needs to extract the common working mode of computing according to the hardware architecture of the computing core. CUDA defines a computing method that combines SIMT hardware multithreading in a master-slave manner. n GPGPU, the computing entity that undertakes each computing task in parallel computing is called a thread.Each thread executes the same instructions during a computing task. Although each thread has different input data and different output results, the instructions that each thread needs to execute are exactly the same. That is to say, one instruction is executed by multiple threads at the same time. This computing mode is very similar to SIMD parallelism, but it is called Single Instruction Multiple Threads (SIMT) computing model in GPGPU. The CUDA programming model combines the GPGPU architecture to reasonably encapsulate the SIMT computing model. CUDA introduces thread grid, thread block, and thread, which can flexibly map computing tasks to GPGPU hierarchical hardware execution units to achieve efficient parallelism and improve processor execution efficiency .
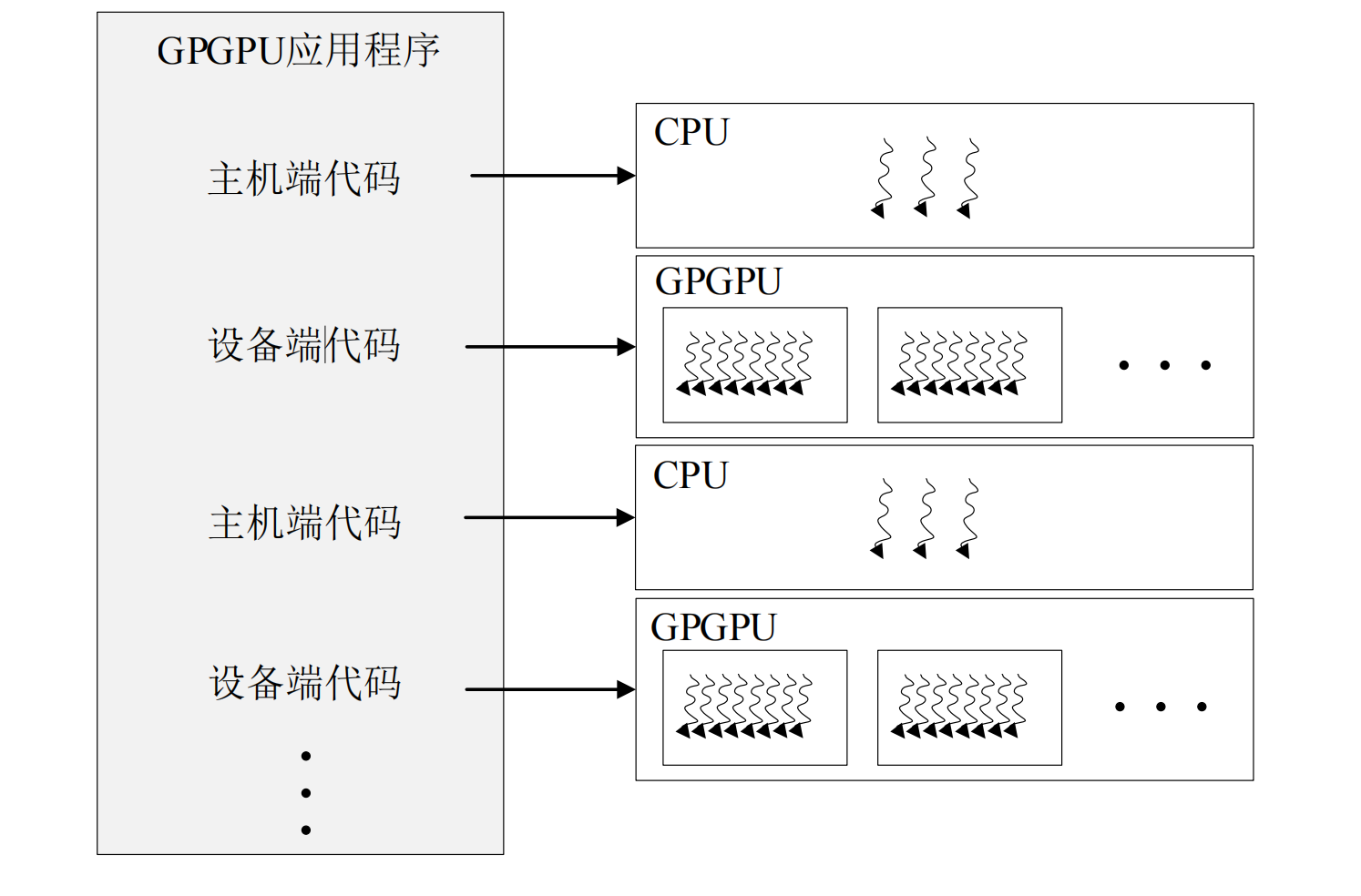
In the CUDA programming model, the code is usually divided into host-side code and device-side code, which run on the CPU and GPGPU respectively. This division is manually calibrated by programmers with the help of keywords provided by CUDA, and then the compiler will call the compilers of CPU and GPGPU to complete the compilation of their respective codes. At the time of execution, the distribution of the host-side and device-side programs is completed with the help of the runtime library. The CPU hardware executes the host-side code, and the GPGPU hardware will further distribute the device-side code to threads according to the parameters such as the thread grid organization method given by the programmer. Each thread executes the same code but processes different data. Obtaining considerable throughput by executing enough threads is the SIMT computing model adopted by GPGPU. The host-side code is usually divided into three steps: data copy, kernel startup, and data writeback.The calculation process is shown in the figure1。
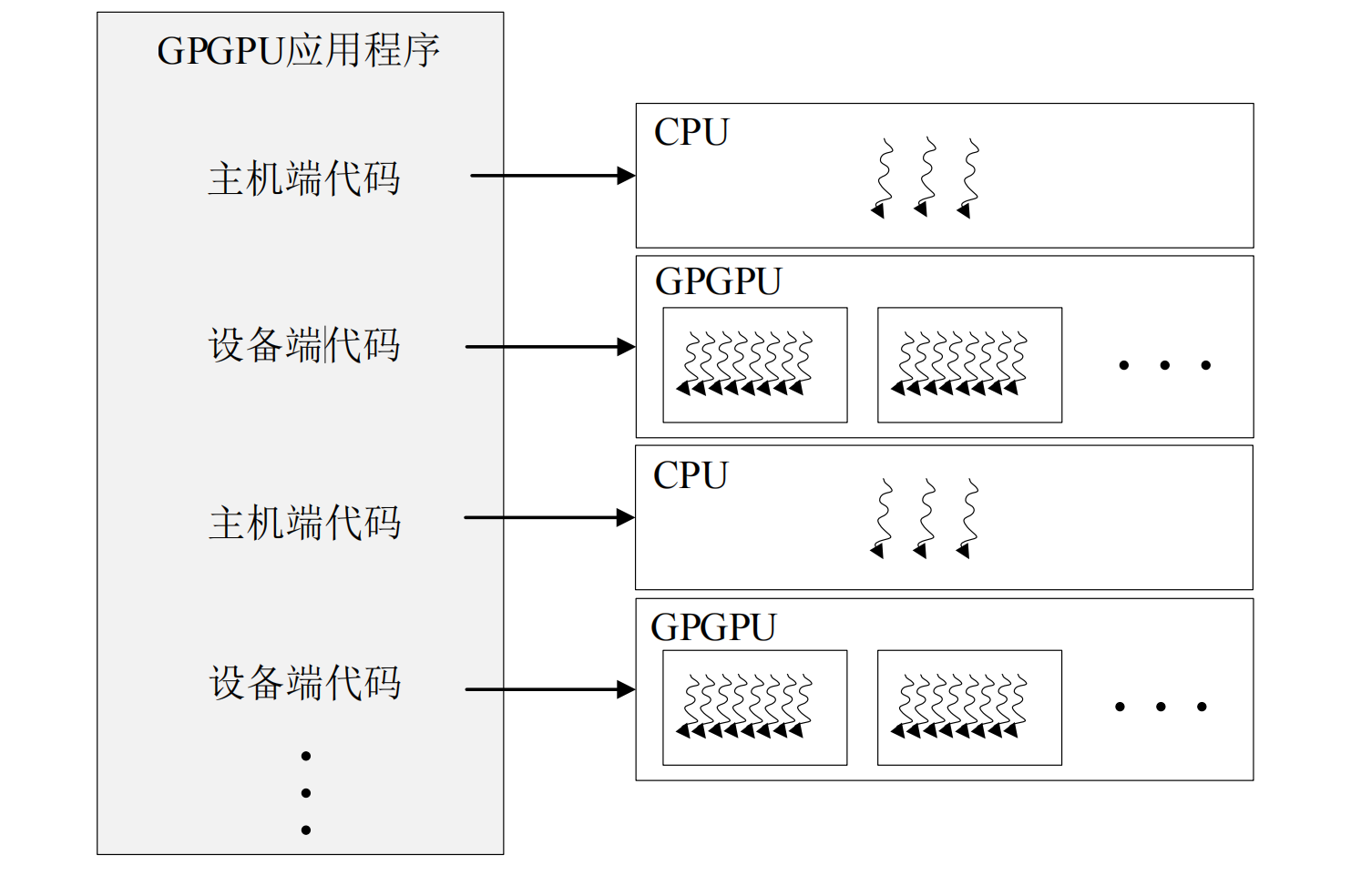{kind=link}
Threading Model
Large-scale hardware multithreading is the basis of GPGPU parallel computing. The calculation of the entire GPGPU device side is organized on the basis of threads, and all threads execute the same kernel function. On the one hand, GPGPU's threading model defines how to leverage massively multi-threaded indexing into different data in computing tasks. On the other hand, the thread organization corresponds to the hierarchical hardware structure of GPGPU. Therefore, the threading model defined by GPGPU becomes a bridge between computing tasks and hardware cores, enabling the programming model of GPGPU to efficiently map computing tasks to hardware structures while maintaining a high level of abstraction.
UDA adopts a hierarchical thread structure. For example, the thread structure defined by CUDA is divided into three levels: thread grid, thread block and thread. Their relationship is shown in the figure2。
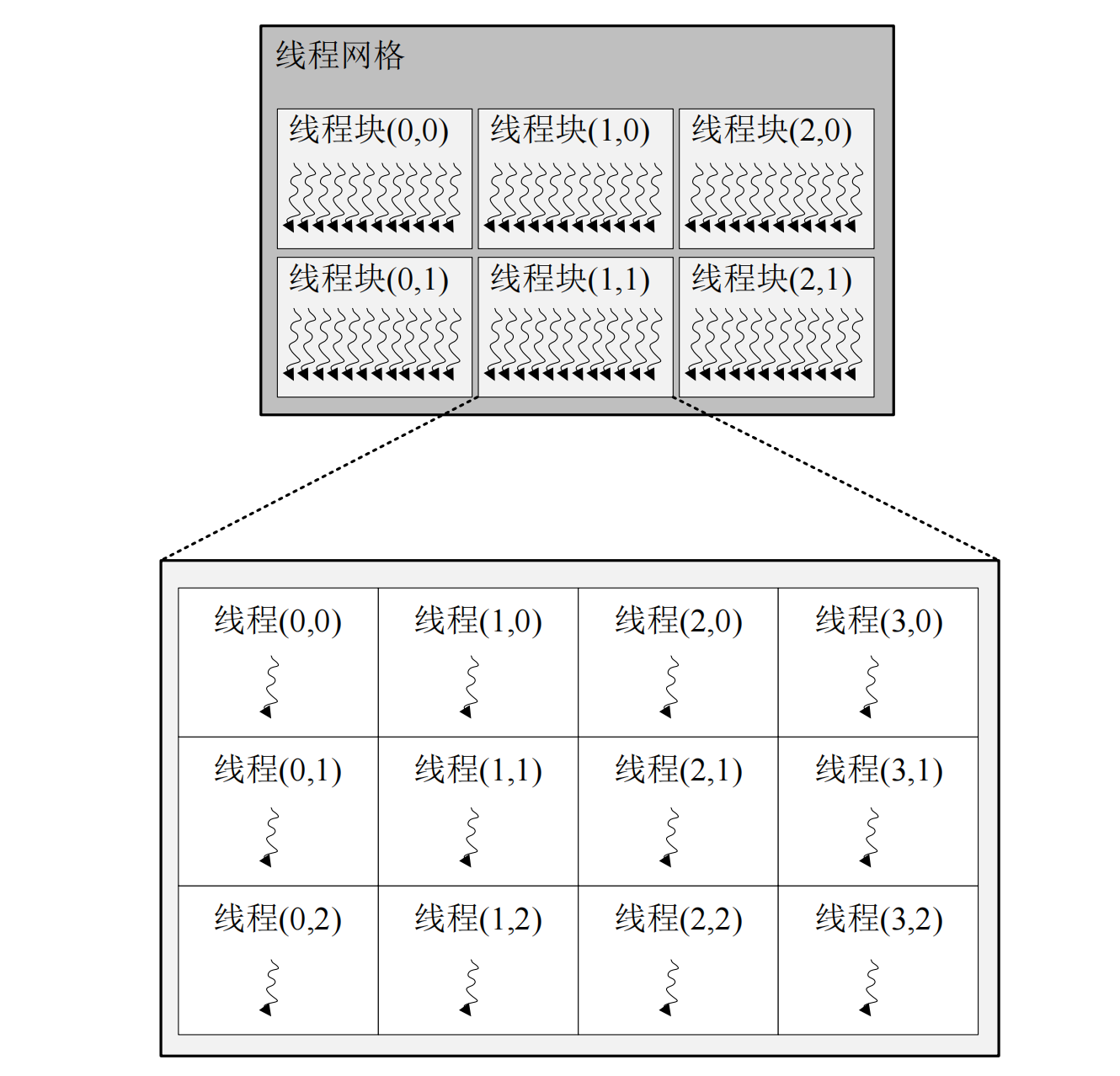{kind=link}
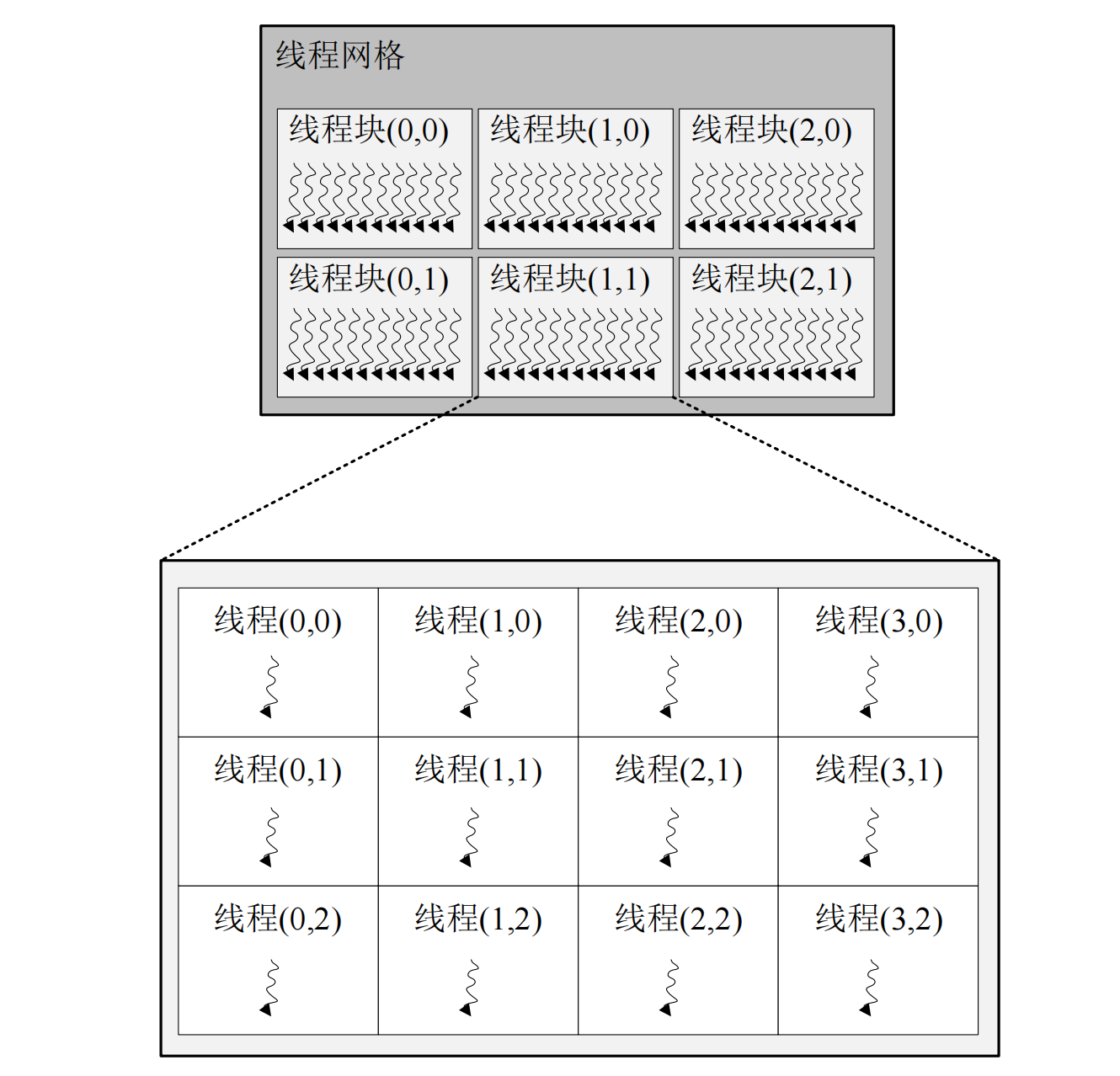
As is shown in the figure 2 ,e thread grid is the largest thread range and contains all threads that are woken up when the host-side code starts a kernel function. The thread grid consists of a number of thread blocks, the number of which is specified by the gridDim parameter. gridDim is a dim3 type of data. dim3 data type is a keyword defined by CUDA, which is essentially an array with 3 unsigned integer fields representing the dimension of the block as three-dimensional, and its organizational structure is x for rows, y for columns, and z for height. As is shown in the figure(../assets/therad-hierarchy.png),the thread grid in the upper part is composed of two-dimensional thread blocks, so set the z of gridDim to 1. If only one-dimensional thread blocks are needed, just set gridDim to a scalar value. A thread block is a collection of threads. In order to divide threads into hardware units at an appropriate granularity, the GPGPU programming model groups threads into thread blocks, and threads within the same thread block can communicate with each other. Similar to the organization of the thread grid, the configuration parameter blockDim of the thread block is also a dim3 type of data, which represents the shape of the thread block.As is shown in the figure(../assets/therad-hierarchy.png), the lower part is a two-dimensional organization of thread blocks, and the organization of each thread block is uniform.