GPGPU概念
GPGPU(General-Purpose compution on Graphics Processing Unit, 通用图形处理器)脱胎于GPU(Graphics Processing Unit,图形处理器)。早期由于游戏产业的推动,GPU 成为专门为提升图形渲染效率而设计的处理器芯片。时至今日,图形图像处理的需求随处可见。因此 无论在服务器、个人计算机、游戏机还是移动设备(如平板电脑、智能手机等)上,GPU都已经成为不可或缺的功能芯片。随着功能的不断演化,GPU 逐渐发展成为并行计算加速的通用图形处理器,即 GPGPU。
GPGPU与并行计算机
Almasi 和 Gottlieb 将并行计算机定义为:“并行计算机是一些处理单元的集合,它们通过通信和协作快速解决一个大的问题”。
从这个定义来看,GPGPU 体系结构也符合并行计算机的定义,而且它明确地采用了类似于单指令多数据(Single Instruction,Multiple Data,SIMD)的设计方式和实现方法,成为当今并行计算机最为成功的设计范例之一。
SIMD是一种典型的并行体系结构,采用一条指令对多个数据进行操作。向量处理器和阵列处理器就是 SIMD 的典型代表。很多微处理器也增加了 SIMD 模式的指令集扩展。在实际应用中,SIMD 通常要求问题中包含大量对不同数据的相同运算(如向量和矩阵运算)。通常情况下,SIMD 需要有高速 I/O 及大容量存储来实现高效并行。GPU 也借鉴了 SIMD 的方式,通过内置很多 SIMD 处理单元和多线程抽象来实现强大的并行处理能力。
GPU和CPU体系结构对比
在面对并行任务处理时,CPU 与 GPU 的体系结构设计理念有着根本的区别。CPU 注重通用性来处理各种不同的数据类型,同时也必须支持复杂的控制指令,比如条件转移、分支、循环、逻辑判断及子程序调用等,因此 CPU 微架构的复杂性高,是面向指令执行的高效率而设计的。GPU 最初是针对图形处理领域而设计的。图形运算的特点是大量同类型数据的密集运算,因此 GPU 微架构是面向这种特点的计算而设计的。设计理念的不同导致 CPU 和 GPU 在架构上相差甚远。CPU 内核数量较少,常见的有 4核和 8 核等,而 GPU 则由数以千计的更小、更高效的核心组成。这些核心专为同时处理多任务而设计,因此 GPU 也属于通常所说的众核处理器。
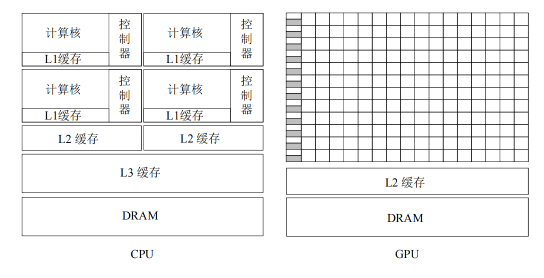
多核 CPU 和众核 GPU 的架构对比如图1所示。可以看到,CPU 中大部分晶体管用于构建控制电路和存储单元,只有少部分的晶体管来完成实际的运算工作,这使得 CPU 在大规模并行计算能力上极受限制,但更擅长于逻辑控制,能够适应复杂的运算环境。由于 CPU 一般处理的是低延迟任务,所以需要大量如图 1所示的一级(L1)、二级(L2)、三级(L3)高速缓存(cache)空间来减少访问指令和数据时产生的延迟。GPU 的控制则相对简单,对高速缓存的需求相对较小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得 GPU 的计算能力有了突破性的飞跃。由于图形渲染的高度并行性,使得 GPU 可以通过简单增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。
{kind=link}
