SIMT相关分析
GPGPU 遵循了 SIMT 计算模型,按照线程束的组织进行指令的取指、译码和执行。这种方式使得编程人员可以按照串行化的思维完成大部分的代码,也允许每个线程独立地执行不同的工作。在执行阶段,如果遭遇了 if…else…等条件分支语句,不同线程需要执行的代码路径可能会不一致,就会出现线程分支或分叉。
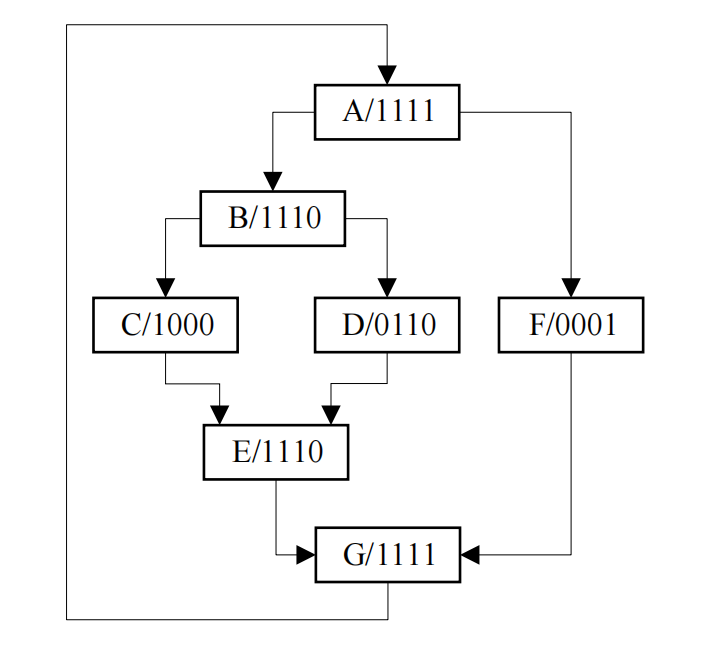
图 1 给出了一个包含嵌套分支的内核函数 CUDA 代码(左)和所对应的 PTX 代码(右)。假设线程束中有 4 个线程。起初,4 个线程执行基本块 A 中的代码,这时没有发生线程分支。但是当指令块 A 到达执行末尾时需要执行第 6 行的 if…else…语句,对应 PTX 第 6 行的分支指令 bra 3 个线程在执行时判断条件成立会去执行块 B 中的代码,而 1个线程不成立而去执行块 F 中的代码,此时就发生了线程分支。同理,执行完指令块 B 代码后也发生了线程分支,一部分线程会去执行 C,而另一部分线程会去执行 D。图 2展示了这段 CUDA 代码和 PTX 代码所提取出的分支流图。其中,每个框表示了需要执行的指令块及哪个线程将执行这个代码块,如 A/1111 表示 4 个线程都会执行指令块 A,C/1000 表示只有第 1 个线程会执行指令块 C。每个框之间的连线意味着相继执行的指令块。
{kind=link}
{kind=link}

